I just had one of those “programming made me happy” moments I thought I’d share.
Background
I’m working on a pure-Elixir markdown parser called earmark. As you probably know, markdown is very poorly specified, which means that each implementation wings it when it comes to edge cases.
Into this void comes Standard Markdown, a valiant attempt to create a specification for this most organic of syntaxes.
As part of their effort, they have a test suite. It’s written as a pseudo-markdown document. The tests are stanzas that look like this:
Here is a simple example of a blockquote:
.
> # Foo
> bar
> baz
.
<blockquote>
<h1>Foo</h1>
<p>bar
baz</p>
</blockquote>
.
The spaces after the `>` characters can be omitted:
.
># Foo
>bar
> baz
.
<blockquote>
<h1>Foo</h1>
<p>bar
baz</p>
</blockquote>
.
The lines containing just dots delimit the tests. The first block is the markdown input, and the second block is the expected HTML output.
They thoughtfully provide a Perl script that runs these tests against your markdown implementation.
I wanted instead to integrate their tests into my overall test suite. This means I wanted to run their tests inside Elixir’s ExUnit.
It turns out to be fairly easy. But, along the way, I learned a little, and I smiled a lot. Here’s a brain dump of what was involved.
What I wanted to do
A normal ExUnit test looks something like this:
defmodule HtmlRendererTest do
use ExUnit.Case
test "something" do
assert my_code(123) == 999
end
test "something else" do
assert my_code(234) > 42
end
end
I wanted to take the stanzas from the spec and create a new ExUnit test for each. The name of the test would be the original markdown, so I could easily identify failures.
Top level—Checking for the spec file
I only want to create the ExUnit tests if the spec file is available. To do this, I use the fact that module definitions are executable code. My overall structure looks like this:
defmodule StmdTest do
defmodule Spec do
def file, do: "test/spec.txt"
end
if File.exists?(Spec.file) do
use ExUnit.Case
#<<<
# generate tests
#>>>
else
IO.puts "Skipping spec tests—spec.txt not found"
IO.puts "(hint: ln -s stmd/spec.txt to spec.txt)"
end
end
The nested module Spec is there because I’m going to need the spec
file name in a couple of places later, and I didn’t want to duplicate
it.
The main flow here is fairly straightfoward—if the spec file exists,
we register ourselves as a test module by calling use ExUnit.Case
and then we create the tests. If not, we write a friendly message to
the console to tell people what to do.
Generating the tests
My next problem was to generate the tests—one test for each stanza in
the spec file. I assumed that I’d be able to write code to parse the
specs, returning a list of maps, one map per test. Each map would have
two keys—md for the markdown and html for the HTML. Given this,
generating the tests looks like this:
for %{ md: md, html: html } <- StmdTest.Reader.tests do
@md Enum.join(Enum.reverse(md))
@html Enum.join(Enum.reverse(html))
test "\n--- === ---\n" <> @md <> "--- === ---\n" do
result = Earmark.to_html(@md)
assert result == @html
end
end
The loop calls StmdTest.Reader.tests (which I haven’t written yet)
to return a list of tests. Each entry in the list is a map containing
the markdown and the HTML. The loop uses pattern
matching to extract the fields.
The second and third lines of the loop are a little tricky.
First, the parser returns both the markdown and HTML as a list of
strings, and each list is reversed. That’s why we call
reverse and join on each.
The interesting thing is why we assign the result to module
attributes, @md and @html.
The reason is that test creates a new scope. I needed to be able to
inject both the markdown and the HTML into that scope, but couldn’t
use regular variables to do it. However, module attributes have an
interesting property—the value that is used when you reference them is
the value last assigned to them at the point of reference. Each time
around the loop, @md anf @html get new values, and those values
are used when generating the test.
You might complain that this means Elixir has mutable variables, and you’d be right. However, they’re only changable at compile time, which I believe is allowed under standard Mornington Crescent rules.
Finally, the name of the test is simplly the original markdown with a little decorative line before and after it. This makes our test failures look something like this:
3) test
--- === ---
`code
span`
--- === ---
(StmdTest)
test/stmd_test.exs:59
Assertion with == failed
code: result == @html
lhs: "<p>`code \nspan`</p>\n"
rhs: "<p><code>code span</code></p>\n"
stacktrace:
test/stmd_test.exs:61
Parsing the spec
 {.right}
{.right}
Parsing the spec file uses two of my favorite programming tools: state machines and pattern matching.
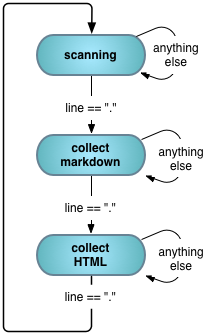
The state machine is trivial.
We start scanning the file. When we find a line containing a single dot, we collect markdown. When we then find a dot, we switch to collecting HTML. When we find one more dot, we’re back to scanning for the next test.
How do we write a state machine in Elixir? We don’t, because Elixir
already comes with the function Enum.reduce. We pass it the
list of lines to process and an accumulator. The accumulator is a
tuple containing the current state and the result. All the state
transitions are then handled by pattern matching. Each pattern
matching function returns a new accumulator—the (potentially updated)
state and result.
Here’s the code:
defmodule StmdTest.Reader do
def tests do
File.open!(Spec.file)
|> IO.stream(:line)
|> Enum.reduce({:scanning, []}, &split_into_tests/2)
|> case(do: ({:scanning, result} -> result))
end
############
# Scanning #
############
defp split_into_tests(".\n", {:scanning, result}) do
{ :collecting_markdown, [ %{ md: [] } | result ] }
end
defp split_into_tests(_other, {:scanning, result}) do
{ :scanning, result }
end
#######################
# Collecting Markdown #
#######################
defp split_into_tests(".\n", {:collecting_markdown, [ %{ md: md } | result]}) do
{ :collecting_html, [ %{ md: md, html: [] } | result ] }
end
defp split_into_tests(line, {:collecting_markdown, [ %{ md: md } | result ]}) do
{ :collecting_markdown, [ %{ md: [line|md] } | result ] }
end
###################
# Collecting HTML #
###################
defp split_into_tests(".\n", {:collecting_html, result}) do
{ :scanning, result }
end
defp split_into_tests(line, {:collecting_html, [ %{ md: md, html: html} | result]}) do
{ :collecting_html, [ %{ md: md, html: [line|html] } | result] }
end
end
There are a couple of things I really like in this code.
First, see how we build the new entry in the result list as we need
it. When we first find a dot in the input, we switch to collecting
markdown, so we add a new map to the result list. That map is
initialized with one key/value pair: md: []. As we collect lines in
the :collecting_markdown state, we add them to the head of that
list.
Similarly, when we detect a dot when collecting markdown, we add an
html: [] entry to our result, and move over to start filling it.
The second cool thing is something that makes me love languages such as Ruby and Elixir.
We normally use case as a control structure:
case File.open("xxx") do
{ :ok, device } ->
read(device)
{ :error, reason } ->
complain(reason)
end
But case is really just another function. It takes two parameters:
the value to test against and the keyword list
containing the do…end block. So it seems like I should be able to
use case in a pipeline—it would receive the pipeline value as its
first parameter.
In this case, I want to do two things. When my state machine
finishes parsing the file, it should be in the :scanning state. If
it isn’t, then something went wrong with the parse. Second, the call
to Enum.reduce returns the tuple { state, test_list }, and I
really just want the list part. I can do both of these by appending
case to my pipeline:
File.open!(Spec.file)
|> IO.stream(:line)
|> Enum.reduce({:scanning, []}, &split_into_tests/2)
|> case(do: ({:scanning, result} -> result))
If the tuple returned by the reduce call doesn’t have a state of
:scanning, I’ll get a runtime error (and the error message will show
me what the invalid state was). And, assuming the state is correct,
the body of the case will extract the second element of the tuple
and return it.
What’s the point?
Is this fantastic code? Of course not. It’s a quick hack to get something I needed working.
But it is enjoyable code. The combination of cool techniques made me
smile, and the unexpected use of case in a pipeline made me really
happy.
And that’s why I still code.
(The full source listing is on github.)

- NickName, E-Mail, and Website are optional. If you supply an e-mail, we'll notify you of activity on this thread.
- You can use Markdown in your comment (and preview it using the magnifying glass icon in the bottom toolbar).